Well, maybe not so hidden, but definitely not advertised.
Vudu has an API that, for the life of me, I could not find advertised anywhere, even with an advanced Google search.
So, I'll take it upon myself to scrape their webpage and dissect their home-grown API for my own use.
First, I open the development tools in chrome.
On the Network tab, I filter by XHR, pick a Vudu movie page and let it roll.
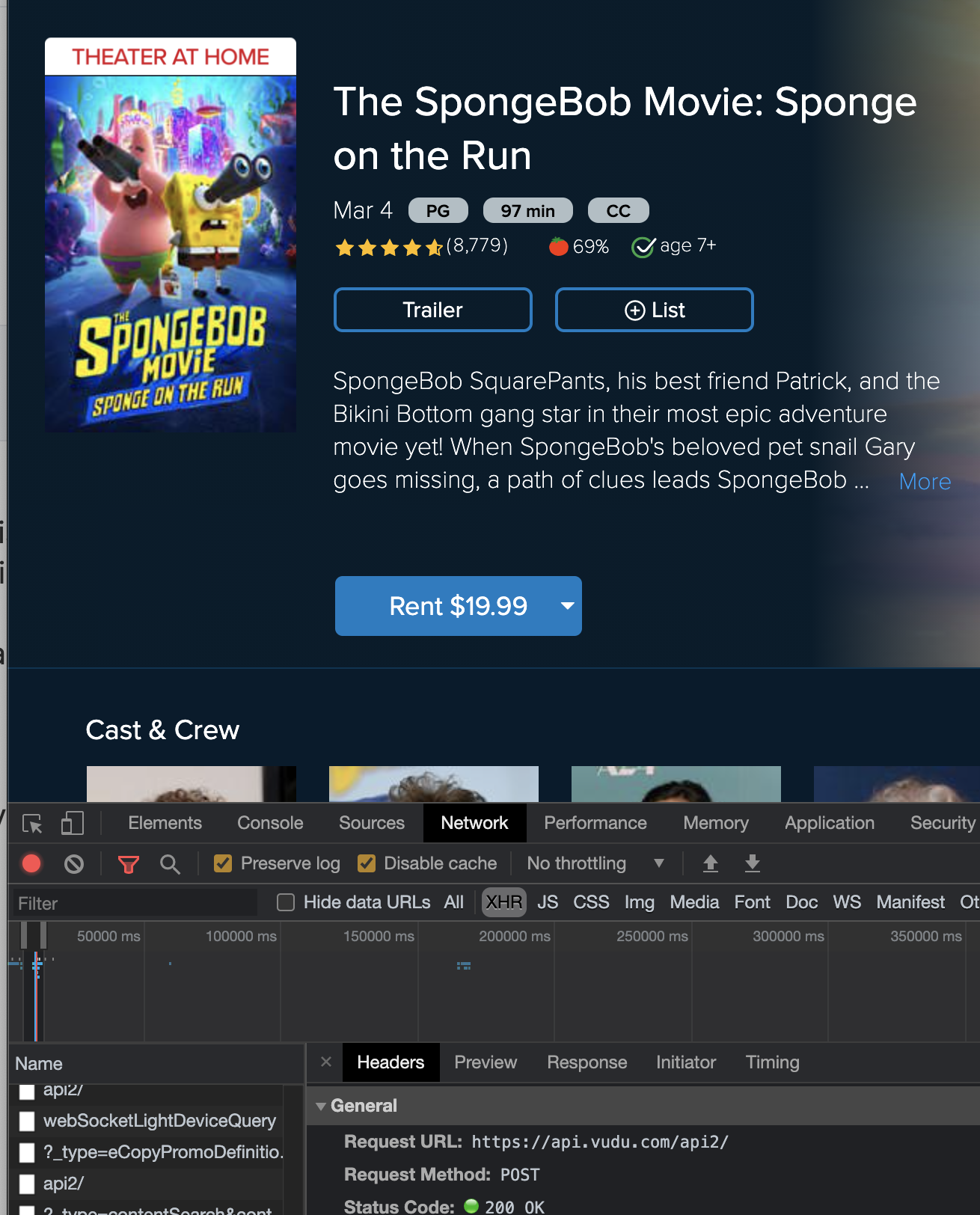
Right away I can see https://api.vudu.com/api2 is a thing.
Let's take a look at what it offers.
Calling that page directly offers nothing, as I expected, but the other calls on this page offer a bit more to work with.
There are several POSTs to api2, but a handful of GETs can maybe get us what we're looking for, like this one:
https://apicache.vudu.com/api2/?_type=contentSearch&contentEncoding=gzip&contentId=1617107&dimensionality=any&followup=ultraVioletability&followup=longCredits&followup=usefulTvPreviousAndNext&followup=superType&followup=episodeNumberInSeason&followup=advertContentDefinitions&followup=tag&followup=hasBonusWithTagExtras&followup=subtitleTrack&followup=ratingsSummaries&followup=geneGenres&followup=seasonNumber&followup=trailerEditionId&followup=genres&followup=usefulStreamableOffers&followup=walmartOffers&followup=preOrderOffers&followup=editions&followup=merchandiseContentMaps&followup=ageLimit&followup=parentalGuide&followup=promoTags&followup=advertEnabled&followup=uxPromoTags&format=application%2Fjson
This is quite a bit of info, but we can maybe work with this.
First, we need to validate this is good json data. Copy the entire results of the page, and punch it into a json validator like https://jsonlint.com/
When we paste in the data, we can see there is some added text for 'secure' and what looks like comments around the whole thing. I'm not sure what that's for, but we can easily strip that out using Python.
Let's create a python script. We'll need JSON and Requests. Create a pipenv or venv and install requests.
Then we'll need to get the text of the request, strip the first part of the invalid json away using lstrip, then strip the last part of the invalid json using rstrip. This will leave us with valid json data that we can then parse to extract the title.
import json, requests
vudu = "https://apicache.vudu.com/api2/?_type=contentSearch&contentEncoding=gzip&contentId=1617107&dimensionality=any&followup=ultraVioletability&followup=longCredits&followup=usefulTvPreviousAndNext&followup=superType&followup=episodeNumberInSeason&followup=advertContentDefinitions&followup=tag&followup=hasBonusWithTagExtras&followup=subtitleTrack&followup=ratingsSummaries&followup=geneGenres&followup=seasonNumber&followup=trailerEditionId&followup=genres&followup=usefulStreamableOffers&followup=walmartOffers&followup=preOrderOffers&followup=editions&followup=promoTags&followup=advertEnabled&followup=uxPromoTags&format=application%2Fjson"
r = requests.get(vudu)
data = json.loads(r.text.lstrip("/*-secure-").rstrip("*/"))
print(data['content'][0]['title'])
Great! We have the title. Somewhere in this mess of json we can get the price too, but rather than creating a nasty mess of list and dictionary calls, I decided to use the internet and borrow someone else's code to dig through json for a specific value.
I found this gist which ultimately led to my final function to parse through json data to get a specific value. I also learned that 'yield' can be used in place of 'return' to return a value while continuing to loop through a function.
def json_extract(key, d):
if type(d) == str:
return d
for k, v in d.items():
if k == key:
yield v
elif isinstance(v, dict):
for result in json_extract(key, v):
yield result
elif isinstance(v, list):
for d in v:
for result in json_extract(key, d):
yield result
I added the type(d) == str to account for an error when the data came back as a string.
So now I can search for the price using this function and get the data I want without having to dig for it manually.
Here's the full script. I left title using the 'old' example just as a reference.
import json, requests
def json_extract(key, d):
if type(d) == str:
return d
for k, v in d.items():
if k == key:
yield v
elif isinstance(v, dict):
for result in json_extract(key, v):
yield result
elif isinstance(v, list):
for d in v:
for result in json_extract(key, d):
yield result
vudu = "https://apicache.vudu.com/api2/?_type=contentSearch&contentEncoding=gzip&contentId=1617107&dimensionality=any&followup=ultraVioletability&followup=longCredits&followup=usefulTvPreviousAndNext&followup=superType&followup=episodeNumberInSeason&followup=advertContentDefinitions&followup=tag&followup=hasBonusWithTagExtras&followup=subtitleTrack&followup=ratingsSummaries&followup=geneGenres&followup=seasonNumber&followup=trailerEditionId&followup=genres&followup=usefulStreamableOffers&followup=walmartOffers&followup=preOrderOffers&followup=editions&followup=promoTags&followup=advertEnabled&followup=uxPromoTags&format=application%2Fjson"
r = requests.get(vudu)
data = json.loads(r.text.lstrip("/*-secure-").rstrip("*/"))
title = data['content'][0]['title'][0]
for t in json_extract('price', data):
price = t[0]
print("%s costs %s on Vudu" (title, price))
I guess that's all for now. Could add more to this later.
-AJ
